



Two things really get me excited: dogs and LLMs. While - sadly - no new dog has been released in a while, guess what just dropped? LLama 3!
Before we begin, grab a can of kombucha, throw it out of the window and make yourself a cup of good coffee ☕️. This is a long post, I need you sharp, not high on the corpses of billions of bacteria rotting in acetic acid!
LLama 3
Meta just released their 3rd iteration of LLama, one of the best open-models available. LLama 3 improves consistently on LLama2 and surprisingly, it competes against much larger models.
LLama3 supports a context window of 8K tokens, twice that of LLama2 and it’s been trained on a 15T tokens dataset, compared to the previously used 2T tokes dataset. The model has been trained on more code (Meta mentions 4x more) on 2 clusters using a gran total of 48.000 GPUs. LLama 3 comes in two flavors: 8B and 70B. The architecture is similar to the previous one, still relying on GQA (Grouped Query Attention) to ensure scalability and lower latency at inference time.
It’s interesting to understand how long it takes to train both a small and a medium-sized LLM. LLama3 8B required 1.3M GPU-hours, which on Meta’s clusters means allocating both datacenters for a total of 27h. What looks like a small number is only because they have a LOT of GPUs.
LLama3 70B required instead 6.4M GPU-hours or both datacenters allocated for 133h or a little over 5 days. Keep in mind that in real-life training runs, not everything goes smoothly. Restarts from checkpoints are quite common, and the frequency of such hiccups depends on multiple factors, so those numbers do not directly translate to the amount of time Meta spent on training the models. Far from it.
In terms of performance, LLama3 8B beats Mistral 7B by a wide margin an all benchmarks, and it obliterates Gemma 7B.
As for LLama3 70B, it stacks up incredibly well against Gemini Pro 1.5 (which is a sparse MoE and I couldn’t find how many parameters per query it activates) and it beats in all tests Claude 3 Sonnet which is in a similar 70B parameters class.

Meta’s Strategy Is Unfolding
While OpenAI took the world by surprise with ChatGPT, Meta took its time to develop a counter-move that I believe will bear fruits throughout the entire 2024, with some interesting ramifications to discuss.
OpenAI has been banking for 2 years on a completely closed ecosystem, to the point that the moniker ClosedAI became the object of various jokes. The advantage of GPT-4 compared to other LLMs has been rapidly shrinking, and it’s not my opinion: today we can run a local LLM on our computers with the same - or better - capabilities than GPT-3.5. Also, Claude 3 Opus continues to outperform GPT-4 in almost every task and benchmark. Yes Anthropic has a worse UI, but in the grand scheme of things, that’s something that can be quickly improved.
While OpenAI enjoys an established customer base, mostly because of their first mover advantage and initial superior performance, Anthropic is rapidly building one too. When capabilities are on-par, or almost on-par, what makes a difference is the ecosystem, the ability to integrate and of course price (and here, Anthropic has some work to do).
Enter Meta.
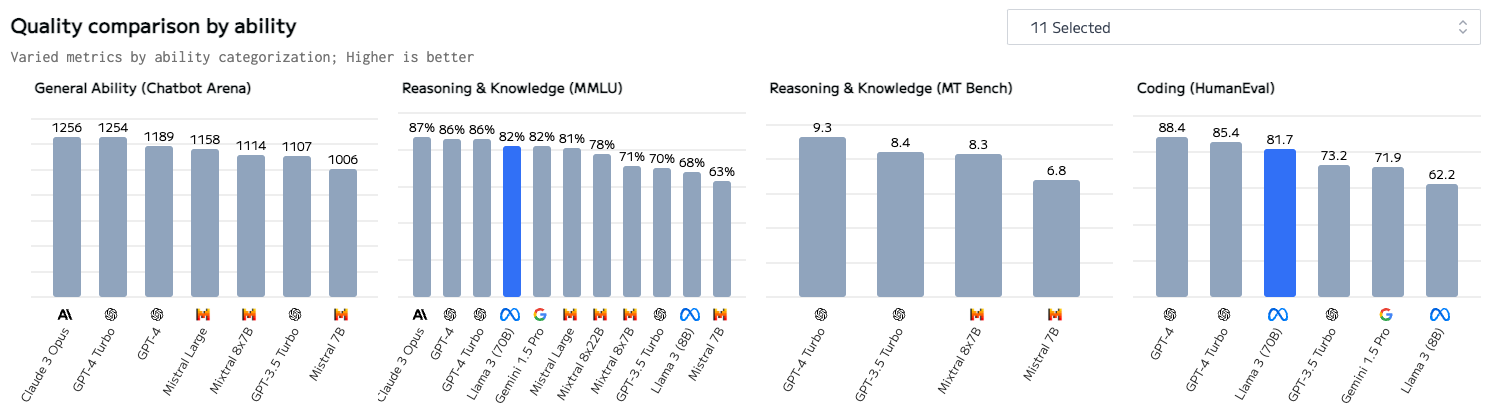
Let’s process this: GPT-4 is not the leader anymore, what’s more interesting is that a medium-sized model like LLama 3 70B sits next to what was, until 3 months ago, the SOTA in LLMs. The mere fact that a model 3-orders-of-magnitude smaller than the best (we are talking about 1.7T parameters across 8x220B experts) can compete at the same table, is to me just amazing - yes LLama3 70B context is much shorter, but you know what I mean. And we are not done yet.

If your business can afford a 12-points loss in performance compared to the SOTA, you can run the same tasks 16x cheaper than GPT-4 and 33x cheaper than Opus!
What, you may ask, if you really really need those 12-points? Very likely you won’t need them for all of your tasks, in which case, you will route your requests to LLama 3 first and whatever is left is sent to either Opus or GPT-4. In all cases, you’ll be saving a lot of money and time. Money that won’t be going to OpenAI or Anthropic (but still to Jensen).
This is an appealing proposition for everyone, from the large enterprise to startups that can now run their iterations with a top-level LLM for very little money, compared to just a few months ago!
And you can bet Meta is not stopping there, we know that they’re training LLama3 400B! My extremely sophisticated estimation method, based on exactly 2 datapoints, puts the training time (using both datacenters) at 22.5M GPU-hours or ~20 days of training time. Certainly a large underestimation.
I know someone will ask, so take my curve and don’t complain!
Double this time to account for restarts and we might expect some buzz coming in summer. Note also they mention models, with an s.
While Grok (with its 314b parameters) didn’t set the state-of-the-art under any metric, Meta has gained a level of know-how that few companies have today, so I wouldn’t be surprised to see LLama 3 400B outperform both Opus and GPT-4 on all metrics and set a new performance standard. Time will tell.
What’s Next?
OpenAI is getting pressed, and I don’t believe for a second that Sora is the answer to their pains. They don’t seem to be preparing any (open) model to compete in the open ecosystem and very likely, their fell behind Meta in terms of raw compute power.
Anthropic sits on an excellent LLM that is performant, fast, reliable and generally very appreciated by their customer base. Opus though is the most expensive of the whole bunch and this might be due to Anthropic struggling to reduce the compute resources required to run inference.
Google is preparing few open models and they are in a unique position to leverage on the capabilities of Gemini, not just with search, in fact both Android and G-Suite are clearly a very good place to start. Nonetheless Google seems to be running a race in a lower class compared to the others.
Microsoft on the other hand, strong of their investment in OpenAI and contractual obligations on OpenAI’s side, might be the one getting the most out of this deal. If OpenAI ends up struggling, Microsoft is going to be the perfect “refuge” for Altman and team.
I’m sure OpenAI’s Q1 and Q2 numbers will be fantastic, in line with their projections and hopefully better, but Q4 will show a different picture of an evolving ecosystem. Unless GPT-5 comes out and blows everyone out of the water. Though at this point, without a technological breakthrough, it’s hard to believe that GPT-5 is going to be 2x better than a future LLama3 400B. But rest assured of one thing, someone from OpenAI will totally claim upon release that they were this close to AGI 😉.
Yet Talents Keep Moving Around
Talent in AI keeps moving around, with Zuck personally emailing DeepMind employees to try and hire them. Yet despite the success of Meta’s AI program, top talent is still flowing out, in directions you wouldn’t expect. Where? And why is that?
While salaries in AI are now the highest in tech and are approaching the highest in general, competing with those in finance, the difference at the top can be marginal. Not everyone would be strongly incentivized to leave a 2M$ package for a 2.5M$ in a different company, but incentives are somewhere else, specifically in the startup world.
Forget about training your own LLM, it probably doesn’t even make sense. Very likely you don’t have the data, you don’t have 48000 GPUs and Jensen doesn’t take you out fishing chips in his tetramethylammonium hydroxide river under the light of a laser-pulsed EUV lamp. So you’re missing all 3 key necessary components: data, GPUs and Jensen’s blessing to buy more GPUs.
If you’re asking what makes sense, let me give you a quick answer. Venture out of your big company and use your expertise to fine-tune existing LLMs or develop products that are highly personalized and cater to very specific needs. The downside? Absolutely nothing. You have made a name for yourself working in a Big Corp and if you fail, your company will hire you back instantly, possibly with a better package. If you don’t fail, chances are you will get acquired by one of those companies you would end up working for anyway.
It’s not that this window of opportunity is going to stay open forever, but now it is and that’s why top talents are starting up their own ventures. For the first time, starting a business has never been less risky, and capital so abundant.
Suddenly Available to Every Phone Near You
Meta strategy makes sense because they can leverage on one of the world’s largest customer base. In fact they have already deployed LLama 3 on their entire product line: Facebook, Instagram, WhatsApp and Messenger.
Mind you, LLama 3 (Meta AI) is not yet available in all countries, but in WhatsApp you can try it in any group chat by writing @Meta AI and asking questions. The same goes for the other apps, there’s also a dedicated website where you can give it a try: meta.ai. If you login with Facebook you can also generate images, but the model lacks visual capabilities, so you won’t be able to ask it to respond queries about images.
In a single move, Meta managed to deploy GenAI to pretty much the entire humankind. WhatsApp counts 3Bn users, Facebook 3Bn as well and Instagram 2Bn, it’s safe to say - net of overlaps in user base - that if you have a phone, you have access to a GenAI assistant without having to do anything other than opening an app that’s already there. That’s no small feat.
When I wrote about OpenAI feeling some pressure, I meant exactly this.
Such a widely available integration, among other things, also helps to introduce a new technology to less technically inclined users. This might be beneficial to many, for instance seniors are increasingly suffering from loneliness - not just them, unfortunately - and chatbots have been proven to help them feel less lonely. This outcome by itself should be a reason for celebration. I might add that a free integration at this level allows those with less or no disposable income, to still take advantage of a tremendously powerful technology. 💪
But Not Everyone is Happy
As you can expect, not everyone is happy about a change that can arguably be seen as a little pervasive. Many people have been asking how to remove the AI assistant, but the answer has been: you can’t. Well, for now you can block Meta AI on the various apps, if you wish, but that might not be a complete solution going forward.
It’s an experimental technology, some mistakes can be dangerous of course, but sometimes they’re just hilarious. The AP reported that Meta AI added itself to a Facebook group of Moms in NYC where it claimed it too had children in NYC 🤣. After being caught in his lie, it wrote:
“Apologies for the mistake! I’m just a large language model, I don’t have experiences or children” and then it disappeared.
Meta AI is apparently more mature than 99% of social media users. And I wouldn’t blame it for trying and feel the vibes of parenthood. In fact, I would have made it a honorary member of the group rather than shoo it out.
There were also a few complaints - rather mild if we compare them with what happened after the release of Gemini - about image generation. So let me introduce you the founders of Google:

And Microsoft:

The same issues about drawing white people (or refusing to, depending on the scenario) that have been plaguing Gemini are somewhat present in LLama 3 as well. At this point, this aspect seems to come with every LLM and image generation assistant, so we’ll get used to it. Though let’s be honest, who doesn’t like Bilal Gates?!
We are living in a fantastic time, where the pressure to compete and deliver on a single technology - well, outside of war times - has never been higher. Companies are trying to fiercely defend their positions with intense research & development efforts. Startups have a newborn technology that can be aligned in every possible direction. To say that all of this is just exciting is an understatement, in fact we are witnessing history being written.
That’s all for today, now go and enjoy that kombucha, if you must!