


AI Update #11
To avoid distractions, please turn off your killer robots.

Apple unveils ReALM aka Siri’s about to get a brain-lift
We’ll all been there:
Hey Siri, call Mom
» Calling Museum of Modern Art
Siri, you can’t be that dumb!
» Don’t call me dumb, I am dumb!
🤦♂️
Now, Siri doesn’t shine bright by today’s standards, but it’s only because it didn’t receive too much love over the years, and that’s about to change. Just about 14 years after its launch, Apple is finally ready for a brain-lift operation that might soon come to an iPhone near you, powered by ReALM, a small LLM.
ReALM is Apple’s attempt at bringing LLMs to the edge, rather than relying on a remote API call. This new LLM has just been presented in a very interesting paper, let’s dive in.
ReALM is not an LLM trained from scratch, but rather a fine-tuned version of FLAN-T5 that Apple have tested in different sizes. The way it works is quite smart: LLMs can only process text, but joint models can do vision & text at the cost of a much larger size, something that a relatively small device, like an iPhone, cannot afford to run, either due to memory or speed constraints, if not both.
To overcome this limitation, ReALM is fed with a description of the screen’s content that is position-aware, in short the LLM knows what’s on screen and knows in which part of the screen a certain piece of text appears. This approach is used to perform reference resolution, or understanding what a human means when they say “find korean BBQs around me…. Ok call the second one”. The “second one” is a contextual reference that possibly applies only in that moment in time and on that device, so this reference needs to be understood by Siri and disambiguated. That’s going to be the job of ReALM: making Siri more aware of the world/context and thus, finally useful!
The benchmarks are quite interesting, as you can see:

Yes, it’s a very narrow task, but in this narrow task, even the smallest version of the model matches or outperforms GPT-4. The dataset is also interesting in that it uses a relatively limited amount of data (without forgetting this is a fine-tune):
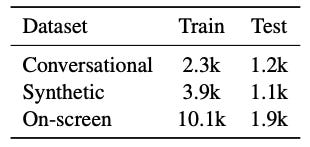
Showing it is possible to deploy efficient and nimble LLMs without sacrificing performance, or like in this case, even outperforming much larger and more expensive models. The same applies to non-LLM based approaches like MARRS. The concept of running models locally, instead of sending data to a remote one, is exciting and hopefully this will promote the wider adoption and development of accelerators on edge devices.
Apple introduced Apple Neural Engine (ANE), their own NPU (Neural Processing Unit), with the A11 and that was 2017. Since then, they continued to invest heavily to expand its capabilities, a sign that there is growing need to deploy on-device AI capabilities.

The same has been done with the M1/M2/M3 series, which today represents one of the best low-cost platforms for AI/ML experimentation, if you can’t afford one or more B100. Hopefully more companies will follow suit quickly.
GPT-4 vs Doctors: when the AI is right for the wrong reasons
A new research published the results of an experiment in which GPT-4 was asked to assess 20 clinical cases (divided in 4 sequential stages each: triage, system review, physical exam and diagnostic testing), against 21 attending and 18 resident physicians. The goal was to measure GPT-4 clinical reasoning capabilities.
Quoting from the research:
Chatbot performed similar to attendings and residents in diagnostic accuracy, correct clinical reasoning, and cannot-miss diagnosis inclusion.
ChatGPT scored 10/10 (rIDEA scoring), attending physicians achieved 9/10 and residents did 8/10. So, the LLM did well, right? Well, yes and no. While ChatGPT outperformed attending physicians, it was wrong way more often than them. Or to put it differently: it was right, but for the wrong reasons.
This experiment shows that benchmarks shouldn’t be taken at face value - and I probably remind you of this in every single update - and that LLMs are not going to replace doctors right away. It shows though that it’s possible to create a clinical workflow with a human in the loop.
It’s not a bad idea to have an LLM come up with a series of findings first, and then have a human doctor correct the reasoning before coming to a diagnosis. Patients prefer to interact with an AI more than a real doctor - and this surprises exactly no one - so this is a good chance to get the best of both worlds, while also taking some cognitive load off the shoulders of doctors working insane hours.
Nvidia GTC
You will want a silicon son after reading this
It happened 2 weeks ago but we haven’t touched it yet: Nvidia GTC came and went, let’s look into what was presented.
It was a warm day in San Jose, California, the sun was shining and the temperature was 24C (or (9/5 × 24) + 32 American degrees) when Jensen Huang enters the stage in a black leather jacket and I wonder: isn’t it a bit too hot to wear that? Most of the audience was wearing shorts.
He opens with: this is not a concert.
And that’s spot on, in fact it feels like it might be one. The arena was completely full and it reminded me of the Moscone Center during the iPhone debut.

Jensen goes through a 2h presentation without breaking a sweat, despite the leather jacket. He shows all possibilities offered by the new Nvidia GPUs, ranging from climate modelling at global scale to digital twins of entire factories and manufacturing lines. The event keeps the audience excited and then he finally announces the new GPUs: B100 (H100 successor), B200 (H200 successor) and GB200 (a single-package dual B200 system) based on the new Blackwell (in honor of David Blackwell) architecture.
Jensen explains that a system of 18 GB200s (containing 36 B200), provides up to 30x increase in LLM inference speed compared to a node of 64 H100. Worth mentioning that the GB200 is liquid cooled.
Let’s understand, for what it’s possible, how these new GPUs compare to the previous ones. On paper this new generation is 5x faster than the previous one, so roughly speaking, a single B100 should be worth 5 H100. In reality the numbers provided are related FP4 precision, so a more fair comparison at FP8 precision would set the B100 at 2.5x the performance of a single H100. Definitely not bad in terms of upgrades but less stellar than depicted.
Keep in mind that these numbers are still calculated with a liquid cooled system vs an air cooled system, which penalizes the air cooled system by a non-negligible margin.
Comparing against AMD GPUs is a bit trickier to do, Nvidia made sure to present the numbers in such a way to make a 1:1 difficult, but you can check an extract here:

Nvidia GPUs are still a little over 2x faster than AMD’s, although it seems that while Nvidia is gaining ground on low-precision computation, AMD is gaining ground on high-precision. As a side-note, when reading the chart keep in mind that sparsity is unfortunately not yet relevant in training and it applies mostly to inference.
Power Consumption and Chiplets vs Gigantic Chips
Two aspects attracted my attention:
The new GPUs are substantially more power hungry, a single H100 consumes 700W, a single B100 uses 1200W. Just to keep things in perspective, a DGX B200 chassis with 8x B200 GPUs requires 14kW (excluding all other components, so the overall total per rack has been reported to be around 60kW)
Nvidia is gradually moving towards a chiplet architecture, moving along the lines of what AMD has been doing over the past few years. This allows Nvidia to achieve neck-breaking interconnect speeds: 10 TB/sec (5 per direction) compared to the 5.2 TB/sec (2.6 per direction) of competing AMD MI300x series
This means datacenters will have to soon accommodate for much higher energy requirements - Amazon just bought a literal nuclear power plant to provide energy to one of its datacenters - if they want to remain competitive in retaining customers with lots of AI workloads.
The second point means that companies, like an all-time favourite of mine, Cerebras, are moving in the right direction. They recently announced their gigantic WSE-3 chip - 57x larger than an H100, and I still don’t know why they keep bragging about how big their chip is if size doesn’t matter, right?? - that should become very competitive, especially for inference workloads.
Single-chip design remove many of the choke points that constrain discrete architectures, but this approach comes with other issues: the cost related to yield and constraints in the amount of memory that can be etched on a single wafer.

Cerebras has demonstrated the potential to outperform Nvidia, at least from certain perspectives. Its single-chip architecture boasts extremely high memory bandwidth, although on-chip memory capacity remains limited. With only 44GB available, it's sufficient to retain a heavily quantized LLama2 model in memory, but handling larger models necessitates extensive streaming.
This is where Nvidia still maintains the upper hand, with systems capable of handling up to 5.7TB of memory (over multiple cards). It’s a race of few big-chips vs many smaller-chips. The outcome of such a race is not yet defined though. Nvidia will certainly remain dominant in the training space, at least in the medium term, but companies like Cerebras could be in the right position to gain important shares of the inference market.
Fab Your Own Silicon Son
What’s the point of being the CEO of the most important company enabling AI for the whole humankind… If you can’t give life to your creatures?
Jensen, probably tired of the traditional biological way to make life, and wishing to take part in the miracle of creation himself, decided to fab his own son and he called him: gr00t.

Satisfied of becoming mother to a metal & silicon baby, he introduced the newborn gr00t to the world. Gr00t was timid at first, the world was very different from the familiar sights of the TSMC clean room were he was conceived, but soon he gained confidence and joined his momdad on stage.
Proud of his creation, Jensen wanted to introduce Gr00t project to the world:

Quoting from their page:
GR00T enables humanoid embodiments to learn from a handful of human demonstrations with imitation learning and NVIDIA Isaac Lab for reinforcement learning, as well as generating robot movements from video data. The GR00T model takes multimodal instructions and past interactions as input and produces the actions for the robot to execute.
The project was announced with videos showing how the framework can help robots learn how to interact with the real-world in a faster and more efficient way, compared to what was possible before.
So far, training a real robot required the creation of a digital-twin in a simulator trained for thousands of hours and then fine-tuned in the real world. The alternative, training a real robot in the real world, is possible but painful.
Gr00t leverages on the scale achievable by Nvidia to train/use new vision and language models to teach robots what to do, and how. This process can take the form of a description, a video or even a direct demonstration.
As real and functional (software) agents appear on the horizon, the ability to train a robotic agent capable of interacting with the real world is definitely exciting. Companies like Boston Dynamics have been pioneers in this space, with incredible results, but the new wave of AI models will enable more companies to achieve similar - hopefully better - results in much less time.
AMD Opensources ROCm with Hardware Documentation
After ZLUDA was put to sleep by Nvidia, AMD stopped funding the project, the blowback to the AI community was discussed at length in previous updates, in case you didn’t read: everyone is sad as that was one smart way to allow the creation of hardware agnostic AI projects.
In what I believe is a counter-move, aimed at least at mitigating part of the damage, AMD announced that they will be opensourcing ROCm (AMD’s version of CUDA). Wait, I hear you asking: wasn’t ROCm already opensource? Wellll… Not really.
ROCm is a stack made of different components, take drivers - the software that allows your computer to actually use a hardware peripheral, say a GPU - those are in theory open source, but in practice they’re only partially open, as what they really do is to wrap a firmware blob (the software that the GPU uses to function). The firmware blobs are, as the term blob implies, a bunch of data that is not readily available for analysis, especially if you’re not a reverse engineer.
The other major deficiency on AMD's part has been the absence of hardware documentation. AMD keeps this documentation very close to their chest, preventing the open source community from contributing with fixes and new features. As an example: if a bug is identified in a driver, the opensource community has little recourse without access to what is called low level documentation. It’s hard to fix a bug if you don’t know how the hardware works.
Hopefully recognizing that so much secrecy only impairs the adoption of AMD GPUs, AMD has taken a step in the right direction. Mind you, they’re not suddenly opening everything, just a little, but it’s better than nothing.
This move should put part of the community in a better position to contribute and stabilize an ecosystem that has suffered from a lot issues and bugs. I’ve read about people working in datacenters having to wait 5 years to fix driver issues that were apparently, quite trivial to solve. The community should be able to take care of such things, if AMD cannot offer the level of support that is expected by a leading provider of hardware.
Amazon walks away from Just Walk Out
Sometimes AI doesn’t mean what we think
I’m sure you remember when, back in 2018, Amazon introduced Amazon Go, a series of mini-markets where you could grab what needed and just walk out without the hassle of the traditional check-out line. As it turns out, Just Walk Out is the name of the powerful technology behind the scenes that automatically tracks what you pick from the shelves and bills you.
Amazon Go was touted as the shop of the future and, back in 2018, people were wondering when this technology would overtake every store. Fast forward to today and, not only it didn’t happen, but Amazon is also walking back on the technology itself and we should understand why.
Amazon had a clear vision when, in 2016, the technology was pitched with the promise of using mostly computer vision models to avoid the need for tagging each item with an RFID. Each store was sort of a surveillance operation, with 100 or more cameras aimed at tracking all possible angles to avoid blind spots. With increasing AI capabilities, Amazon was expecting between 25 and 50 human reviews per 1000 sales.
A little over a year ago, that metric was still not met, in fact Amazon required 700 reviews per 1000 sales. As recently announced, the AI driven shops were truly managed by 1000 contractors based in India. The role of AI (Artificial Intelligence and not Actual Indians) was so minimal that it had no practical effects on an operational intensive activity such as a mini-market.
Despite the progress of AI, some tasks in the real world remain quite difficult to tackle, even in artificially perfect conditions. Something as simple as picking up a toothbrush and putting it back, can confuse sophisticated algorithms, let alone “simple” computer vision models. This is where approaches like V-JEPA might make a difference in the future, and better combine AI with real-world interactions.
That’s all folks, see you next time!