


AI Update #12
Your triggers, your responsibility.

Pretty much everyone: “we have a new chip!”
And I’m not even joking. The chip-race is intensifying, as companies grow tired of depending exclusively on Nvidia, all hyperscalers and chip manufacturers are coming up with their own custom designs.
Intel Unveils Gaudi3
In an effort to compete with Nvidia’s H100 - which has been freshly superseded by the new Blackwell-based B100 and B200 - Intel has introduced their shiny new Gaudi 3. The new chip is 2x more power efficient than an H100 and 1.5x faster. We should put a couple numbers up to understand how Gaudi 3 stacks up against the H100, but I’ll also throw AMD and the B100 in the mix.
Let’s take a moment to enjoy the glory of LaTeX, because Substack doesn’t support tables. Unless you’re on mobile of course, in which case your fingers are now trying to squeeze and drag the image to no avail. Your effort is futile, your frustration won’t be repaid, consider yourself warned!
Since it took me an hour to compile and verify this table - because none of the vendors make this process easy - I’d like to dig into the numbers a bit.
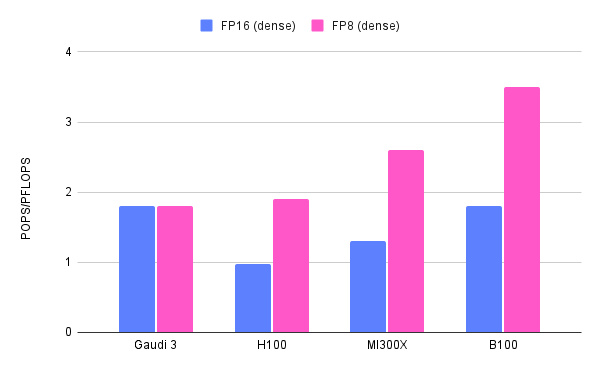
There are a lot of considerations to be made. An important one is that while Nvidia focuses mostly on AI workloads, other companies, like AMD, excel at high precision calculations (used to run simulations, more than AI), so different vendors cater to different needs. But this post is called AI Update, so whether we like it or not, we will stick to AI workloads.
Gaudi 3 comes out roughly 2 years after the Hopper architecture and thus the H100. This chip is manufactured with a 5nm process, so it is possible that Intel, that just announced their 5nm process, is relying on an external foundry.
Obligatory reminder here that nm (as in nanometers) has nothing to do - not anymore at least - with the size of anything on a chip. When you see nm written somewhere, it identifies a manufacturing process for a specific generation. A 5nm node has in fact an (interconnect) pitch of 30nm. Surprisingly, the way you decide to call something 5nm or 7nm, is somewhat defined by the International Roadmap for Devices and Systems.
5nm is aptly defined as “the MOSFET technology node following the 7nm”. And that makes sense considering how much each generation changes the way a node is manufactured. To add confusion, companies sometimes rename their processes in seemingly random ways, but I don’t want to go down that rabbit hole.
Gaudi 3 shows remarkable performance in FP16 on par with their FP8 performance, this is no small feat, as in general you get roughly double the speed as precision is cut by half. The improvement - on FP16 - is on par with the Nvidia B100 but it still lags behind the newly announced B100 in FP8.
Intel is working hard to ensure Gaudi stays relevant, unfortunately they didn’t announce anything about the price, besides “it will be competitive” - at least they didn’t say: we are thinking of pricing it… Twice as much as Nvidia. All in all, assuming a sensible pricing strategy and good supply, Intel is in a good position to capture part of the inference market this year. Gaudi 3 is, at least on paper, very performant despite relying on a previous generation manufacturing process compared to Nvidia.
The reason I mention only inference is related to the chip’s memory. Gaudi 3 ships with 128GB of HBM2e memory, clocking in 3.7 TB/sec. That’s more than the original H100 (that came with 80Gb) but less than the B200, that comes with 192GB of new generation HBM3E that clocks in 8 TB/sec. So Gaudi 3 might be a perfect fit for smaller models training (say GPT-3.5 and below) but larger models will benefit greatly from the added and faster memory offered by the new B100/B200.
Google Unveils ARM-based chips
Google joined the ranks too with the announcement of a new chip, ARM based, aimed at reducing energy consumption and offering better performance than equivalent Intel CPUs. This is not an AI-specific design, more an overhaul of an existing infrastructure to take advantage of what is a fantastic architecture. Now, how cool would it would be to see a RISC-V server too on a hyperscaler??
Meta Announces Next-Gen MTIA
We discussed MTIA (Meta Training and Inference Accelerator, why do I suspect Yann named this too?!) in a previous update, now Meta has announced its next-generation. For some reason they haven’t called it Gen2, it’s just Next-Generation MTIA. Since chipicsTM are the new sexy - or so I’m told - get this:

This new chip is fully integrated with PyTorch 2, Meta developed a dedicated Triton-based compiler (a great idea indeed) to churn out code for the accelerator, and to allow developers to experiment with compute kernels. In terms of specs, the new MTIA comes with 128GB of DDR (off chip memory) and it achieves 0.35 TFLOPS in dense INT8 General Matrix Multiplication, which is really not bad considering this small beast has a TDP of just 90W.
It’s clear that all large providers are either experiencing or forecasting an important increase in AI-workloads across their products, and they’re getting ready. Custom chips are expensive to design, and companies need to develop and maintain the software stack necessary to use them, but this effort pays off in the longer term.
The first-gen MTIA was designed to accelerate (mostly) Meta’s recommendation engine, while this new generation appears to cater to different needs as well, such as running your own LLMs. Now if we could only get some of these… chips….
Mistral Releases Mixtral 8x22B
Mistral has just released a new and larger Mixtral (the version using a Mixture-of-Experts), the previous version was 8x7B params, this one is a slightly more massive at 8x22B.
Cool down your GPUs and free your VMEM because you’ll want to use it. Performance, so far, are really great:

Mistral keeps delivering and they’re gaining - even more - the community’s love for improving on the state of the art at all model sizes.
The new Mixtral outperforms Cohere Command R+ in 3 benchmarks out of 6 but… Command R+ is a 104B parameters model, while Mixtral only activates 39B parameters per query! Mixtral outperforms GPT-3.5 on all metrics, and it’s roughly in line with Claude 3 Sonnet (Anthropic’s second largest model).
We don’t know exactly how large is Claude 3 Sonnet, some estimates put it at around 70B parameters, so if Sonnet doesn’t use an MoE, this makes the new Mixtral roughly 2x more efficient than Claude 3 Sonnet on a per-parameter basis. Take this with a pinch of salt though, as I’m making 2 assumptions: model size and architecture used.
A new high-performance model at a reasonable size is absolutely welcome, it brings (free tier) ChatGPT-level performance to the masses, and this is a lot considering it’s only been 16-months since ChatGPT’s debut. This new Mixtral can be run, quantized at 4-bit, on an M2 Mac with 256GB of ram. It really won’t be long until such capabilities become available on-device for everyone, rather than via an API call to a cloud server.
Introducing Udio and Suno
A team of ex-DeepMind employees released Udio, a very fun AI-music synthesis service. Imagine it like StableDiffusion but for music. I admit having way too much fun writing a song about the hardship of chip design, and you should totally listen to it.
I’m sure you loved it (right?), but you should also listen to someone who actually knows how to make music. It’s hard not to love something like this, and musicians are already discussing both the quality and implications. I must say that, unlike what happened when StableDiffusion was released (total chaos), musicians are approaching this in a very civilized way (kudos to you all). I’ve extracted a comment at random:
I ended up playing around with this until 1 am. It is honestly amazing what this can create.
I let it generate lyrics based on topics and if you took one of these full songs I generated and played it for a random person, they would not have no idea this was AI generated.
The style, the voices, the rhythm, all of it. The way it can extend seamlessly to add more to it. It's highly impressive
And it really is impressive. As you can see from the screenshot above, you can add elements where you like (drops, solos, specific instruments etc) and over time I’m sure the model will only become easier to steer and more precise. Imagine creating your own tracks and finally mixing them in minutes. This brings music creation to literally everyone with a desire to create music, whether they’re proficient musicians or aberrations - like yours truly - barely capable of strumming a Ukulele without setting it on fire.
I’ve been listening to random songs - some of which were just hilarious - while writing this entire update. I forgot it was not my Spotify until someone started to sing Lorem ipsum dolor - with a great Latin pronunciation - and I was like: which band is singing Lorem ipsum??? It was no band, it was the AI. Thank you AI gods for breathing life into a 2000 years old book. I’m sure Cicero was happily vibing in his tomb, way to go my friend!
Udio was shortly preceded by Suno, which shares pretty much the same UI and very similar capabilities, it’s good to have two players in the same space.
I don’t like thinking that Art is going to be disrupted by AI. Rather, tools like StableDiffusion, Udio, Sora and also all LLMs, allow the average caveman to create something that they wouldn’t otherwise be capable of. If I imagine these same tools in the hands of professionals artists, I can only imagine the wonders they’ll be able to come up with as this technology evolves.
Protests and boycotts won’t stop AI from getting widely adopted, and once the inevitable is embraced, we will move to stage 2 where human creativity gets empowered and amplified by one of the most powerful technologies ever created.
Debunking Devin (some more)
You’ve already heard about Devin and the “amazing capabilities” it promised. I was one of the skeptics from the moment they released the demo and, as it turns out, I really wasn’t alone. Last week a few videos have been surfacing, providing deeper analyses of the demo and resizing, significantly, Devin’s capabilities.
Feel free to watch the videos I linked, this one is probably the best choice, though it’s rather technical, so if you struggle with a terminal, you won’t get much. In summary though: when something sounds too good to be true, it probably is. Don’t get dragged by the hype, as too many have done, and try to remain objective.
The world of software development is experiencing a revolution, AI agents will replace many software development jobs and eventually AI will be capable of writing, testing and deploying large projects to production. Not just yet though. Like art, engineering too will be profoundly impacted, not by Devin.
See you on the next update!