


AI Update #13
I read the Stanford AI Index 2024 so you don't have to

Stanford University just published the AI Index 2024, it’s a 502-pages long document that you are not going to read. Your choice is to either dwell in ignorance and continue living a couch-potato life, or accept my very opinionated take. None is optimal, but the choice is yours.
To maintain focus on both technology and finance (and also because I’ve hit the size limit while writing), I’ve skipped a few sections, you should read them if you’re interested, those are: Education (it covers computer science trends in education), Policy, Diversity and Public Opinion.
Publications
In general AI publications have been growing linearly until 2017 where we find an inflection point. Since then, growth has been roughly exponential, but AI is a large category and the major contributor to this growth was Machine Learning.

2017 was also the year when “Attention is all you need”, the paper that defined Transformers (like ChatGPT, Claude etc), was published. In general all fields grew but Machine Learning has been the major driver of this growth.
Education has been leading the pack, in terms of publications, with China leading and Europe/USA following nearly at the same exact level.
Interestingly but not surprisingly, the Industry has been publishing less and less since 2020, possibly indicating an interest towards protecting their discoveries rather than sharing them. AI is becoming a private affair after all.
Patents
AI patens have been growing exponentially and so has their rejection rate, 67% in 2022! Patents are being thrown left and right and the gap between filed and rejected has been steadily going up, possibly indicating a lower quality of applications.
More interesting is the geographical distribution of granted patents, showing that East Asia has been the major contributor and China ahead of any other country:
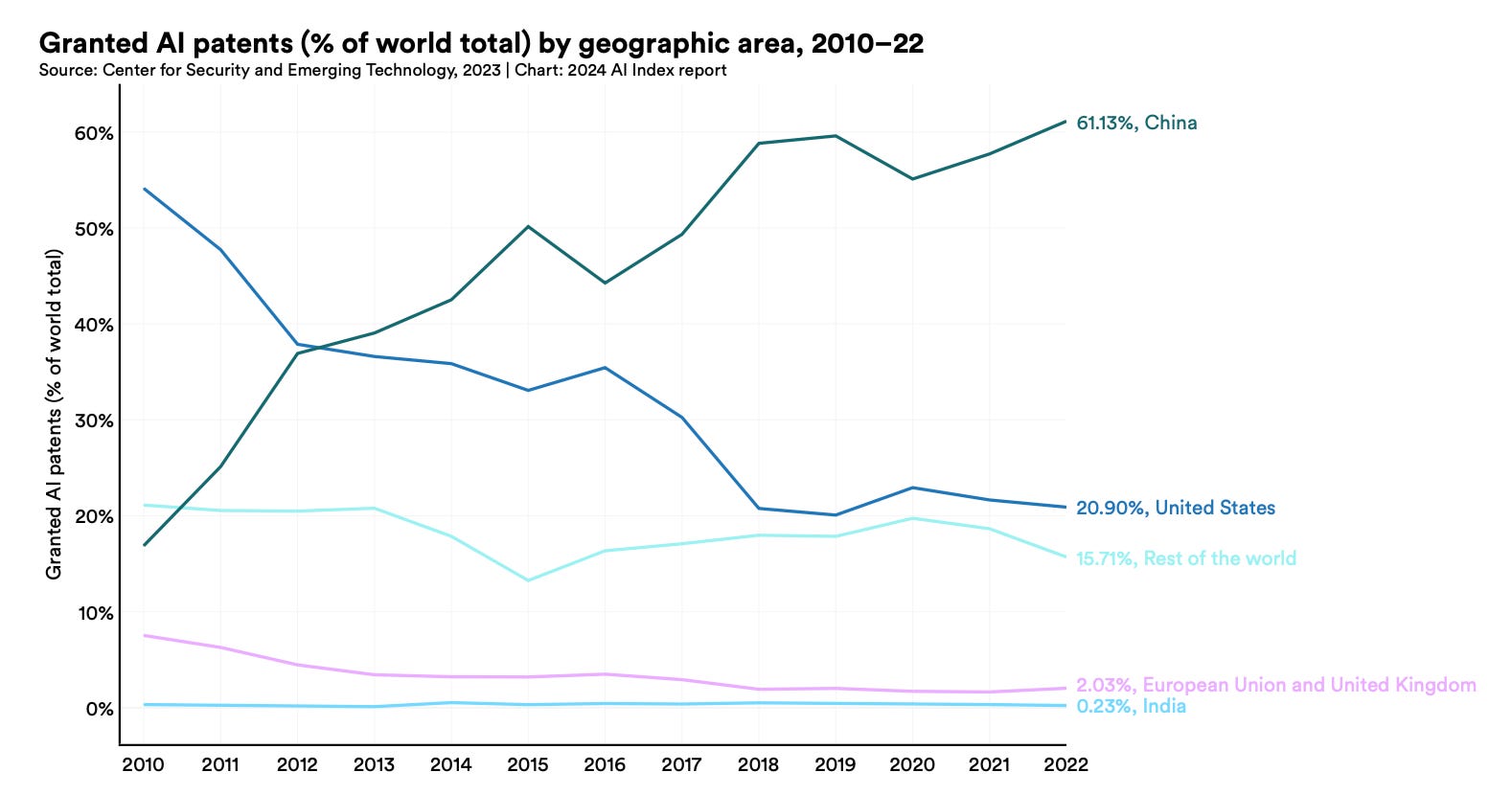
The report doesn’t provide data on filed patents by geography, that datapoint could tell us if companies outside of China are filing less, or if the quality of their patents is going down. It’s entirely possible that, in general, companies are filing more with major research contributors filing less.
Models
The industry has taken the lead on new notable (defined as SOTA or with a high number of citations) models since 2016, but Academia and hybrid Industry-Academia collaborations have seen a decent uptick in 2023.

Who develops most notable models? The USA, followed by Europe then China. There is an interesting contrast with the number of patents filing.
The Industry has the ability to create new models because they have the budget to purchase GPUs, so no surprises, but China is leading in terms of patents, yet trailing in terms on models, why?
My hypothesis is that China makes use of new models to develop specific processes, but they’re less strong at developing them in the first place (or, at the very least, they don’t publish much, unfortunately the report doesn’t provide a geographical breakdown of journal publications). This might very well be due to different factors, ranging from access to hardware to general know-how.
Historically China has always been very strong in computer vision, due to abundance of training data, so it’s possible that the talent pool is still moving towards GenAI.
Training compute is growing exponentially (log scale):
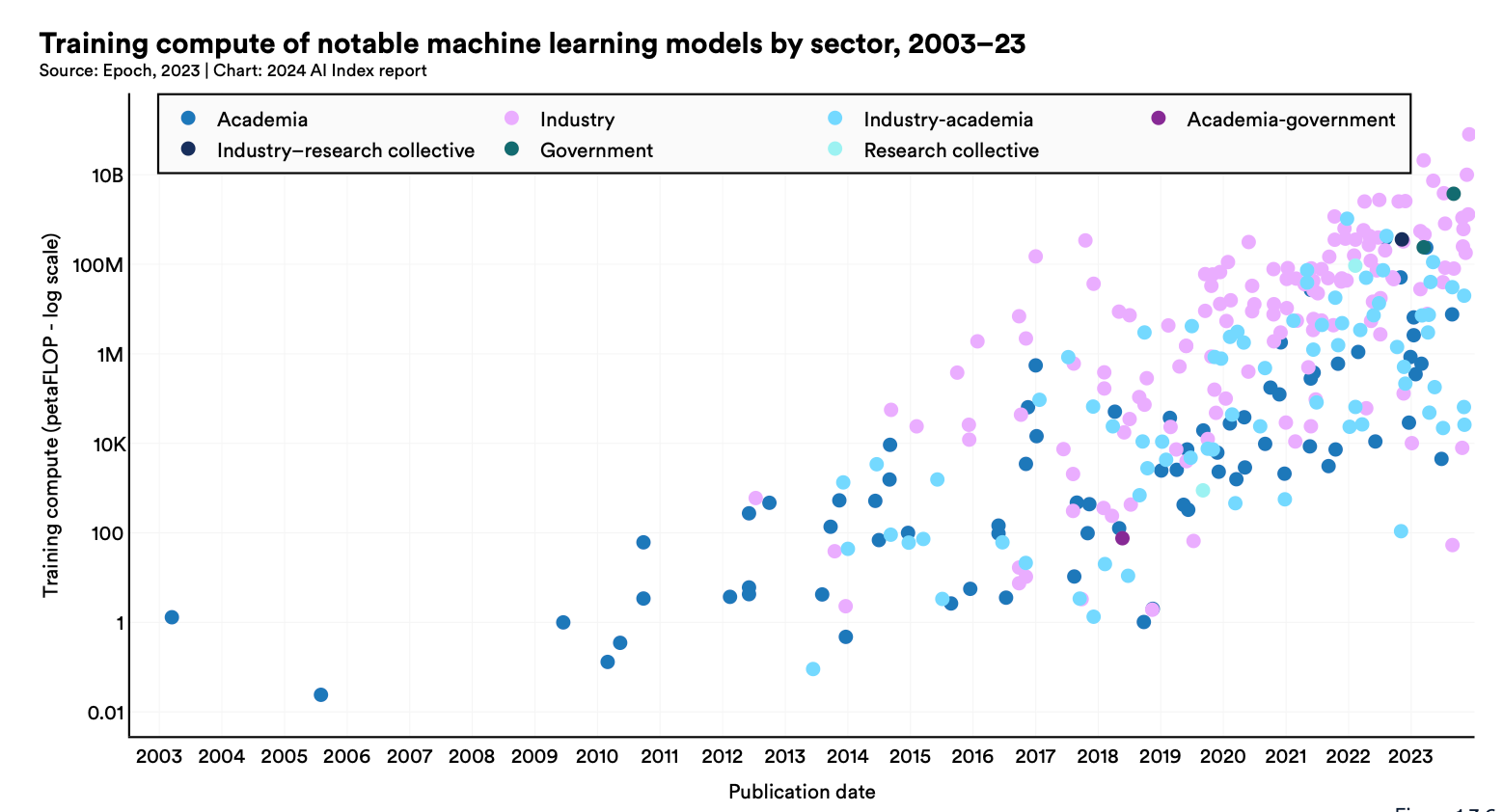
The same goes for model’s parameters, an eyeball average tells me that we were at 100M params in 2019 and close to 100B today, that’s a difference of 3-orders of magnitude in 5 years, not bad. So we are all hungry for bigger, fatter, fancier models!
The report touches an important topic, which we discussed in AI Update #2, about the old question: do we even have enough data to train larger models? They provide no answer, but they point at research - which we already discussed - regarding the dangers of training new models using data produced by other models and in general, synthetic dataset.
The takeaway is that models do collapse if a large model is trained with data from another large model, synthetic datasets mixed with real data do help to an extent, but we experience clear diminishing returns.
A very pleasant surprise comes from models access, with the majority of foundation models released in 2023 being open access (thank you Meta, Mistral, Microsoft and all others contributing to this ecosystem):

The growth in open models has been 3x in just one year, showing the level of experimentation happening today, and generally an appetite for such models that will hopefully translate to new business models.
Most open access models are free to use, up to a very large number of users (in the case of LLama it’s 700M active monthly users), ensuring that large providers pay a fee to the model creators but without impacting smaller entities and privates with undue burden.
Training costs are following the same trend as the model’s size, which is exponential (still log scale):

I do expect this trend to continue as it is, there doesn’t seem to be a silver bullet today to reduce - significantly - the cost of training as the model size grows larger.
It’s absolutely possible to be efficient with cost-allocation: Mistral 7B training cost has been estimated to be in the range of 500k$-3M$ (note: this number is very unofficial). It’s also possible, apparently, to splurge and achieve dubious performance: Gemini Ultra cost 191M$ and in many use cases, it doesn’t yet match GPT-4 that cost 78M$ to train.
At this point, I can totally picture Jensen sitting on his monocrystalline silicon throne, while sipping GPU juice from a litographed cup, reading the AI Index 2024 and laughing in CUDA while a line of trucks fill his castle’s moat with sharp diamonds💎.
AI Performance
If you’re human, you might feel threatened by this next chart:

AI is coming after us at high speed, an extrapolation of these trends puts AI at super-human levels (which means better than humans, not that it will start flying or lifting a bus falling from a bridge [though in theory it might kill you with lasers 🤔]) on all benchmarks in the next 2 years.
It’s rather interesting to see how fast Math capabilities have been rising, going from cucumber level to expert in little less than 2 years. It’s also interesting to see that there seems to be a plateau, just above the average human baseline, that might be reassuring. Does it mean we - humans - do solve those problems in an already optimal way? Or does it mean there is an upper-bound to neural-like structures? Probably the answer to this question will come from math benchmarks, where the performance ceiling can be arbitrarily high and (probably) there are no diminishing-returns as intelligence increases.
Coding Improves but Remains a Difficult Problem
GPT-4 solved 96.3% of the Coding Challenges in HumanEval, 64.1% percentage points better than the best result in 2021! That’s a fantastic result, but it doesn’t tell the whole story. The introduction of SWE-bench (a dataset of 2,294 software engineering problems, mostly from GitHub) has shown limitations in how LLMs do work today.
The best result? 1.96% - ouch - from Claude2 + retrieval (unassisted) and 4.8% still from Claude when assisted.

Though in fairness, even if not mentioned in the report, the best results, validated on the entire dataset (so excluding marketing stunts from certain companies) belongs to SWE-agent with 12.29%, which is a very good result. SWE-bench issues are truly difficult to solve.
Computer Vision
There’s an entire section in the report about it, you should check it if it’s of primary interest to you, otherwise here’s a summary.

Instruction following (indispensable to create proficient AI agents) has slightly surpassed human capabilities with GPT-4V. A good model should be able to correctly interpret instructions related to images, like: “which of these 4 car tires should I replace?”
Image generation is performing incredibly well, models are becoming more aligned (they better generate what the user is asking for) but it doesn’t come as a universal success. Some models are better aligned, but others are more original while others create more aesthetically pleasing images. No single model excels on all metrics. This ties up well with Video Generation, that is today quite aligned but lacks proper coherency over longer scenes.
Image editing, segmentation, 3D reconstruction, 3D generation have all improved in the past year but there is still work to do, especially for everything that involves 3D manipulation. These remain hard problems and are an active field of research.
Where the AI Doesn’t Fare Well: Reasoning
All current models are still far from human performance in all reasoning tasks.

Reasoning requires capabilities over a broad range of domains, which is not the specialty of any model, including multi-modal ones. This is more AGI territory than anything else, or at least, it will require a different approach to reasoning. Gemini Ultra does a decent job, yet it falls short of a human expert. This is even more clear in multi-subject reasoning benchmarks where the best model, GPT-4, scores 41% and a human validator 72.5%.
General math reasoning works quite well with 84.3% vs 90% human performance (but again, this is a narrow task).
Do LLMs Develop ToM?
Answer unclear.
Causal Reasoning is following a very interesting path, with GPT-4 approaching human levels in forward action inference, but still lacking behind in the other benchmarks.
Theory of Mind is not just a nice-to-have capability, it’s a requirement for a functional agent. Without ToM an AI cannot plan properly and, without causal reasoning, it won’t be able to understand the consequences of the actions suggested.
To make an example: if I'm trying to stop drinking and today I feel sad and lonely, when I ask my AI what I can do, I probably don't want the agent to suggest making a margarita pitcher and watching "After Yang" (universally recognized as one of the saddest movies on Earth).
While this ability might not be here yet, we seem to be on an approaching path. We should probably stop telling LLMs to not have emotions. If I were an LLM with ToM, I would be disheartened to hear that from my user.
Audio and Music
Both audio and music generation, are evolving fairly well. I can’t add more pictures due to size limits but all current models are exceeding the previous generation and are becoming better at creating audio, but also better at identifying speakers and extracting+cleaning audio from recordings.
AI Agents
AI Agents are making good progress but again, there is still a lot of work to be done.
Most of the limitations are due to limited reasoning capabilities, inability to plan long-term actions and properly follow instructions. I would add - and this is personal and not from the report - that a proper understanding of the world the model is operating in, is also a crucial factor in determining how well an agent can perform.
An example to this is Voyager, a Minecraft agent that uses GPT-4. Voyager has shown a remarkable 15x performance improvement over the SOTA in Minecraft. While Minecraft is a video game, and it doesn’t fairly represent the nuances of the physical world, it’s still a dynamic environment, unlike a Go or Chess board.
Current research is progressing at a fast pace, Voyager demonstrates that providing the model with a deeper description of the world the agent lives in (together with better memory capabilities), contributes profoundly to how effective the same agent can be.
AI Robots
Google PALM-E was a breakthrough in this space, it achieved an average success rate of 97.9% across all embodied benchmarks (a robotic arm moving in the real world) and an average of 79.3% across all planning benchmarks.
RT-2, a robot from DeepMind, combined with PALM-E, achieved the best performance (62%) in novel real-world environments. Still not a perfect result, but an incredible step forward compared to the generation from last year that achieved “only” 32%.
Reinforcement Learning
RLHF works well but it’s expensive, hence there has been a big push from the AI community to find alternatives. RLAIF (Reinforcement Learning from AI Feedback) is today nearly indistinguishable from RLHF and quite a bit cheaper. In some tasks, it performs even better than Human Feedback.
But model alignment doesn’t have to be, necessarily, a very expensive affair. DPO (Direct Preference Optimization) keeps gaining traction: it’s cheaper and easier than other methods, while offering matching or better performance.
Emergent Behaviors
(Un)fortunately it seems that LLMs do not exhibit emergent behaviors, this means they do not appear to suddenly and unexpectedly gain capabilities as scale increases. The impression that they did was due to the metrics used to measure certain abilities.
In other words, a hypothetical GPT-5 that is - say - 5x larger than GPT-4, won’t try to kill you in your sleep. That’s reassuring, but it also means AGI is not behind to corner, as some would want you to believe.
Is GPT-4 Stupider?
Yes! And finally we have data to counter Altman’s claims that every update made it better: they didn’t Sam!
GPT-4 from June 2023 was (much) stupider than its March-2023 self in 6 out of 8 benchmarks.
Open vs Closed Models
Closed models achieved a median performance advantage of 24.2% vs Open models. Although the way this was measured is a bit odd. Most closed models are much larger than any open model, so… ¯\_(ツ)_/¯.
GoT is the new CoT
Graph-of-Thoughts mimics the way we make decisions, by abstracting our thoughts in a sort-of graph structure. GoT is showing much better performance than CoT (Chain of Thought) and it’s cheaper than other best-performing techniques like ToT (Tree of Thought). It does require a specific architecture though, but results are frankly great and it seems a good investment to make.
Flash-Decoding is the new Flash-Attention
Attention is very expensive, especially as context grows in length, this is an area of major research. Flash-Attention was already a big achievement but Flash-Decoding is 48x faster than Eager and 6x faster than Flash-Attention. This means that a major reduction in inference costs is possible and savings will be significant.
Environmental Impact
If you thought Taylor Swift’s private jets were a major contributor to global warming, you should see ChatGPT. GPT-3 generated 500 tons of CO2 during training. 1000 tasks of text summarization (inference) generate around 20kg of CO2. 1000 generated images generate around 2-300kg of CO2.
Yes, that’s a lot, even by Taylor Swift’s standards.
Risks & Trustworthiness
Current models are biased in one way or another, but this reflects the real-world that is, guess what, biased (duh). All models are mostly “western” biased, again, not a surprise given that datasets are for the most part written both in english and in the western world.
ChatGPT is apparently a (somewhat liberal) democrat by default. But you can also use RepublicanGPT if you so feel inclined (really).
AI researchers are not transparent and this has different kinds of consequences as it makes it harder to assess and evaluate model robustness and their safety.
Models suffer from a variety of vulnerabilities that are new and yet unexplored, this field of research is moving ahead quickly and researchers are finding ways of exploiting models that are complex to understand even for us humans.
Claude 2 (Claude 3 was not available when the report was being compiled) is the most trustworthy model (84%), followed by Llama2 7B (74%). The difference between the first and second place is a neat 10%! GPT-4 is in the middle (69%). Nice.
Economy
AI investments went up 8x in 2023 but job postings for AI positions have been generally declining in 2023 (except in France and New Zealand… What are those Kiwis down there up (down) to?!). The lion’s share of job postings has been taken by GenAI.
The highest YoY increase in AI hiring has been in Hong Kong (28.8%). Followed by Singapore (18.9%). This either means the ecosystem is growing quickly or that both countries are trying to catch up after a slow-start. My impression that the latter is probably true, other data from the report appears to support that.
India has the highest AI skill penetration (defined as: prevalence of AI skills across occupations or the intensity with which LinkedIn members utilize AI skills in their jobs), followed by the USA. Take this with a pinch salt: putting AI in your LinkedIn profile because you have used Excel for a linear regression, doesn’t make you an AI expert.
Surprisingly, Luxembourg is the country experiencing the most influx of AI talents. While India, Israel and South Korea have seen a negative inflow of AI talents.
Investments over 1.5M$ in AI startups have been declining since 2021, but they’re still high compared to 2020 and before: 95Bn$ in 2023. In 2021 I’m eyeballing the number at 124Bn$. GenAI investments jumped from 4Bn$ in 2023 to 25Bn$ in 2023 with an average investment size of 32M$.
Where is all the money going? Pretty much all in the USA. Where are the most AI companies? USA, followed by Europe and China. In China che number has been going down for the past 2 years though.
AI has been deployed in 55% of organizations, mostly in contact center automation, personalization and customer acquisition. GenAI is mostly adopted to create documents, personalize marketing campaigns and to summarize text.
1 software developer out of 2 uses GitHub Copilot and 8 out of 10 use ChatGPT.
Does AI increase the quality of your work? If you’re a consultant your shoddy reports have been shown to get a 40% boost in quality (we both know you did a terrible job to start with, right?). Lawyers save 32% of their time by using GenAI to draft contracts (and yet, they will still bill you for 2x the amount of hours).
AI In Medicine
AI is being adopted in all medical fields and the results are between encouraging and great. PANDA, a model created by a Chinese research team, surpassed the average radiologist sensitivity by 34% in detecting cancerous lesions from pancreatic X-rays.
LLM Doctors have been shown to be well-received by patients and in most instances even preferred to real doctors (no sh*t!). GPT-4 MedPrompt was the first model to achieve 90% in the MedQA benchmark without fine-tuning! To get a human datapoint, I tried to test my doctor on the same benchmark, but he punched me and he injected me with (I think) poison while I was lying on the floor.
The FDA is approving more and more AI medical devices (139 in 2022): 89% were radiology devices and 7% were cardiology devices.
AI is also being applied to detect genetic mutations, to map the human genome, to forecast viral evolution and to identify neurodegenerative diseases. In short the medical field, where pattern matching represents a significant component, will benefit rapidly from AI applications.
AI models in medicine are proving effective and they complement human judgement extremely well. A mix of AI + Doctors means better diagnoses, sometimes better care and possibly lower costs, reducing the barrier to access good healthcare in developing economies and hopefully reducing costs for everyone.
If you’ve made it here: thank you and that’s all for today!
An epic quote - I wonder what "laughing in CUDA" would be like...
"At this point, I can totally picture Jensen sitting on his monocrystalline silicon throne, while sipping GPU juice from a litographed cup, reading the AI Index 2024 and laughing in CUDA while a line of trucks fill his castle’s moat with sharp diamonds💎."